
CNN의 내용
What is a CapsNet or Capsule Network? 의 내용을 요약 정리함.
이 내용은 먼저 CNN을 알고 있다는 전제 하에서 설명한다. CNN에 대해서 궁굼한 사람은 관련 자료를 미리 보고 오기를 바란다.
CNN은 본질적으로는 많은 수의 뉴런을 쌓아 올려서 구성하는 시스템이다. 이것은 이미지 처리에서 매우 효과가 좋은 것으로 입증되어 있다. 하지만 이미지의 픽셀 단위로 뉴럴 네트웍을 구성하므로 많은 수의 계산 비용이 발생하는 문제점이 있다.
따라서, 컨볼루션은 데이터의 핵심을 잃지 않고 계산을 단순화 시킬 수 있는 방법이다. 컨볼루션은 기본적으로 행렬에 대한 곱셈과 그 합의 결과물이다.
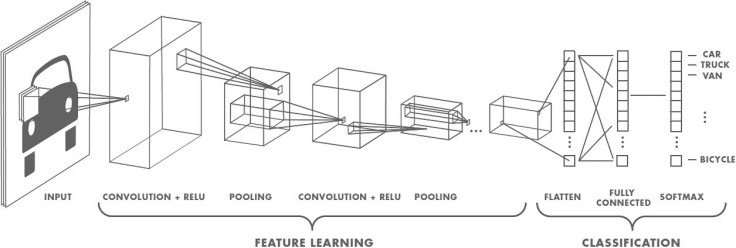
이미지가 네트웍에 들어오면 커널과 필터들이 스캔하고, 컨볼루션을 수행하게 된다. 이것을 통해서 특징 맵을 네트워크 내부에 구성하게 된다. 이것은 활성화 계층과 폴링 계층을 지나게 된다. 활성화 계층은 레이어의 비 선형성을 유도해야 한다. 폴링은 학습 시간을 줄여주는 역활을 수행하게 된다. 폴링 계층의 기본적인 생각은 각 부분별 영역에 대한 요약이 되는데 이로 인해서 대상 인식에서 위치라던가 변형에 대한 invariance를 가지게 된다.

사람들은 위의 변형을 쉽게 이해하지만 CNN은 같은 것으로 인식하지 못한다. https://medium.com/ai³-theory-practice-business/understanding-hintons-capsule-networks-part-i-intuition-b4b559d1159b
마지막으로 분류 네트워크로 진행하게 되고 이를 통해서 적절한 분류를 통해서 레이블링을 넣게 된다. 학습은 분류 결과의 오류를 기반으로 back propagation을 수행하면서 이루어진다. 비 선형성은 이 단계에서 vanishing gradient를 해결하는데 도움을 주게 된다.
CNN의 단점 내지는 문제점
CNN은 이미지 분류에 탁월한 효과를 가지게 된다. 하지만 이미지가 흔들리거나 회전하거나 혹은 하여튼 원래 이미지와 조금 틀리게 구성되면 CNN의 성능은 낮아지게 된다. 이 문제는 하나의 이미지에 대해서 다양한 변형을 통해서 해결하고 있다. CNN의 각각의 레이어는 이미지를 세분화 시켜서 이해하고 있는 알고리즘이다.
만약 배와말을 분류한다고 하면 첫번쨰 레이어는 작은 커브와 경계를 이해하고, 두번째 레이어는 직선과 작은 모양을 이해하는 방식으로 진행하게 된다. 높은 레벨로 갈수록 점점더 복잡한 모양을 이해하게 된다. 마지막으로 높은 레벨로 이동하게 되면, 전체 말이나 모양을 이해하는 단계로 진행하게 되는데 우리는 각 단계별로 폴링을 수행하므로 위치 정보에 대한 정보등을 놓치게 된다.
폴링은 위치에 대한 invariance를 가지게 해 주지만 반대로 이미지와 데이터가 원래의 이미지나 데이터에 근접한 것만 이해하게 된다는 단점을 가지고 있다. 이로 인해서 정확한 위치나 모양이 아닌 경우에도 잘못된 판정을 하게 된다. 사람들은 이 차이를 명확하게 알 수 있지만, CNN은 구분을 잘 못한다. 폴링 레이어는 이러한 종류의 invariance를 가지고 있다.
이러한 단점은 폴링레이어에서는 의도된 것이 아니다. 폴링은 위치, 방향 비율에 대한 invariance를 얻는 것이 목적이지만, 실제로는 모든 invariance까지 다 얻게 된다.
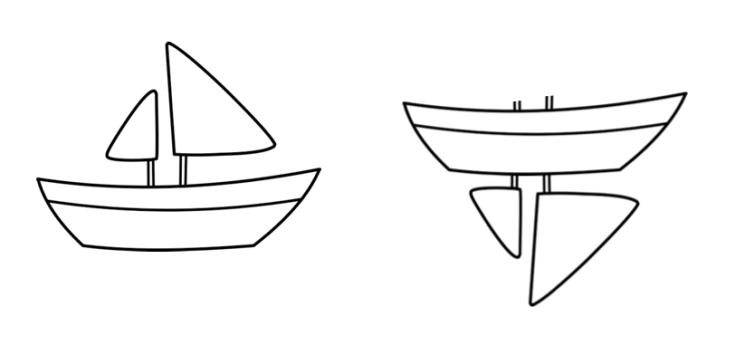
우리가 원했던 것은 Invariance가 아니라 Equivariance이다. CNN은 배의 크기가 줄어들었어도 여전히 배인 것을 인식하게 된다. 이것이 최근의 Capsule Network을 이끌어가게 된다.

Capsule Network란
뉴럴 네트워크는 매일 매일 발전하고 있다. 이 분야에서는 많은 똑똑한 사람들이 발전을 이루어내고 있다. 최근에 Release된 것이 “Dynamic Routing Between Capsule”을 논문으로 나왔다. 이 논문은 딥러닝계에 충격을 주었다. 이 논문은 Capsule, CapsNet에 대해서 이야기하고 있다.
이 논문 저자들은 인간의 뇌를 capsule이라 부르는 단위로 부르고 이것을 다양한 자극에 반응 할 수 있도록 만들었다. 예를 들어서 위치나 방향, 크기 속도 등등등…..
뇌는 “routing”이라는 메카니즘을 통하여 낮은 레빌의 시각 정보 다루는데 capsule이 최적의 구조임을 이야기하고 있다.
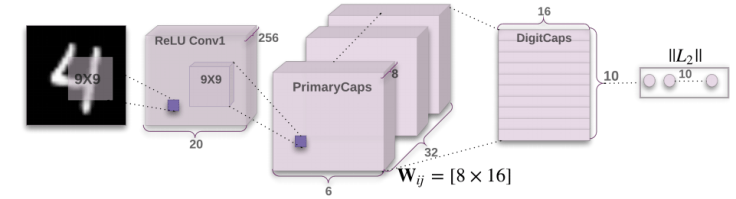
캡슐 넷은 신경층을 중첩시켜서 만든 네트워크이다. 일반적으로는 단일 네트워크 상에서 계속 레이어를 쌓아가면서 만들지만, 캡슐넷은 레이어 안에서 캡슐이라는 개념으로 레이어를 계속 병렬로 쌓아가는 구조를 가진다.
캡슐의 내부 신경 상태에서 하나의 특성을 포착하여서 엔티티의 존재를 나타내는 벡터를 출력한다. 벡터의 방향은 엔티티의 속성을 의미한다. 벡터는 신경망의 모든 부모 네트웤으로 보내진다. 가능한 부모 캡슐은 예측 벡터를 찾아 낼 수 있다. 예측 벡터는 자기가 가지고 있는 가중치와 가중치 매트릭스로 만들어진다. 특정 부모 캡슐은 가장 큰 예측 벡터를 만들어내고, 캡슐간의 연결을 증가시키게 된다. 나머지 캡슐은 연결을 감소시키게 된다. 이 “routing by agreement”는 현재 사용하는 maxpool 방식보다 훨씬 좋은 결과를 낸다. max pool 방식은 하위 레이어에서 강한 특징을 찾아내는 것을 목적으로 하는 방식이다. dynamic routing 외에도 캡슐 넷에서는 squash 처리를 한다. 이 처리는 비 선형성처리이고, CNN에서 하는 것 처럼 각 레이어에 추가하지 않고, 레이어의 중첩 세트에 추가할 수 있다. 이 것은 각 캡슐의 벡터 출력에 적용이 된다.

위의 함수가 SQUASH 함수인데, 캡슐 넷에서 잘 동작한다고 논문에서 설명되어 있다.
이것은 벡터가 작으면 0으로 만들려고 하고 크면 1로 제한하려고 한다. 이 방식은 계산 비용을 증가시키지만 확실하게 효과는 있다.
이 논문은 Capsule Net이 전체적으로 검증이 완전하지 않다는 것을 알고 있어야 한다. MNIST에서 검증은 되었지만, 전체적으로는 아직 많은 검증이 필요하다. 몇일 새에 아래와 같은 지적.고려가 필요하다고 이야기되고있다.
- 벡터의 길이가 엔티티가 확률적으로 있다는 것을 의미하지만, 길이를 1 이하로 유지하기 위해서는 반복 계산으로 라우팅이 만들어지는 것을 최소화 시키는 합리적인 비 선형 함수가 필요하다,
- 두 벡터의 코사인 값을 이용해서 계산하는 이 계산 법은 gaussian cluster의 log variance와는 다르게 아주 좋은 agreement와 좋은 agreement를 구분하지는 못한다.
- n개의 요소를 가지는 행렬로 계산하지 않고 벡터를 사용하므로 변환 행렬은 2*n개의 파라미터를 이용하여 계산한다
캡술과 뉴런의 차이점 비교

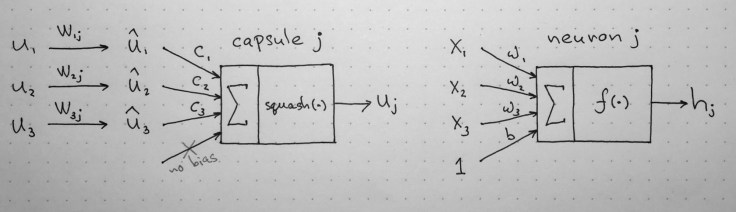
캡슐은 affine trainsform을 입력으로 하는 것외에는 구성이 비슷하다.
- matrix multiplication of input vectors
- scalar weighting of input vectors
- sum of weighted input vectors
- vector-to-vector nonlinearity
수식에 대한 설명은 아래 그림에서 참고

“Understanding Dynamic Routing between Capsules (Capsule Networks)”
– 파이썬 코드와 함께 자세하게 설명함.
– 논문과 함께 읽으면 이해에 도움이 됨.
CapsNet paper review
- 논문에 대한 리뷰
Capsule Networks: An Improvement to Convolutional Networks
- 설명

댓글 남기기